
TTS Text to speech on Linux Arch, Ubuntu, Gnome KDE
Arch, Ubuntu, CentOS; KDE & Gnome
The journey so far
My new post about A.I. voices can be found here.
I have wanted to switch all my computer use over to Linux for many years. When I first tried Linux in 2011 I started going through all the software use cases I had and ticking them off, but I could not find any text to speech software that worked in a way I wanted, however even back then I found workable solutions for everything else. I started off as many people did with Ubuntu and used that on and off on old computers until 2018. I used CentOS on my web server from 2015 and continue to this day (I will switch this out for Rocky Linux at some point in the future).
Here is my first ever post on TTS from 2013, written when I was trying seriously for the first time to switch my main computer over to Linux: https://ubuntuforums.org. Long story short, I failed and carried on using OSX. Since then, every few years I have returned to this issue doing online research to see if I can find new information on suitable text to speech options. Everything else I need is already built for Linux, but this still remains a bit of an issue for me, due to the way I Use TTS.
Why I use text to speech. My English ability is very poor (dyslexia), I have a reading and spelling age in English of a 12 year old child. Everything I write and much of what I read I use my computer to read back. I use the built in function in OSX that lets me assign a keyboard command to do TTS, which for me is the command + 3 key on my keyboard to read back any text in any application using the computers inbuilt TTS voices (This is available from System Settings » Accessibility » Speech in OSX).
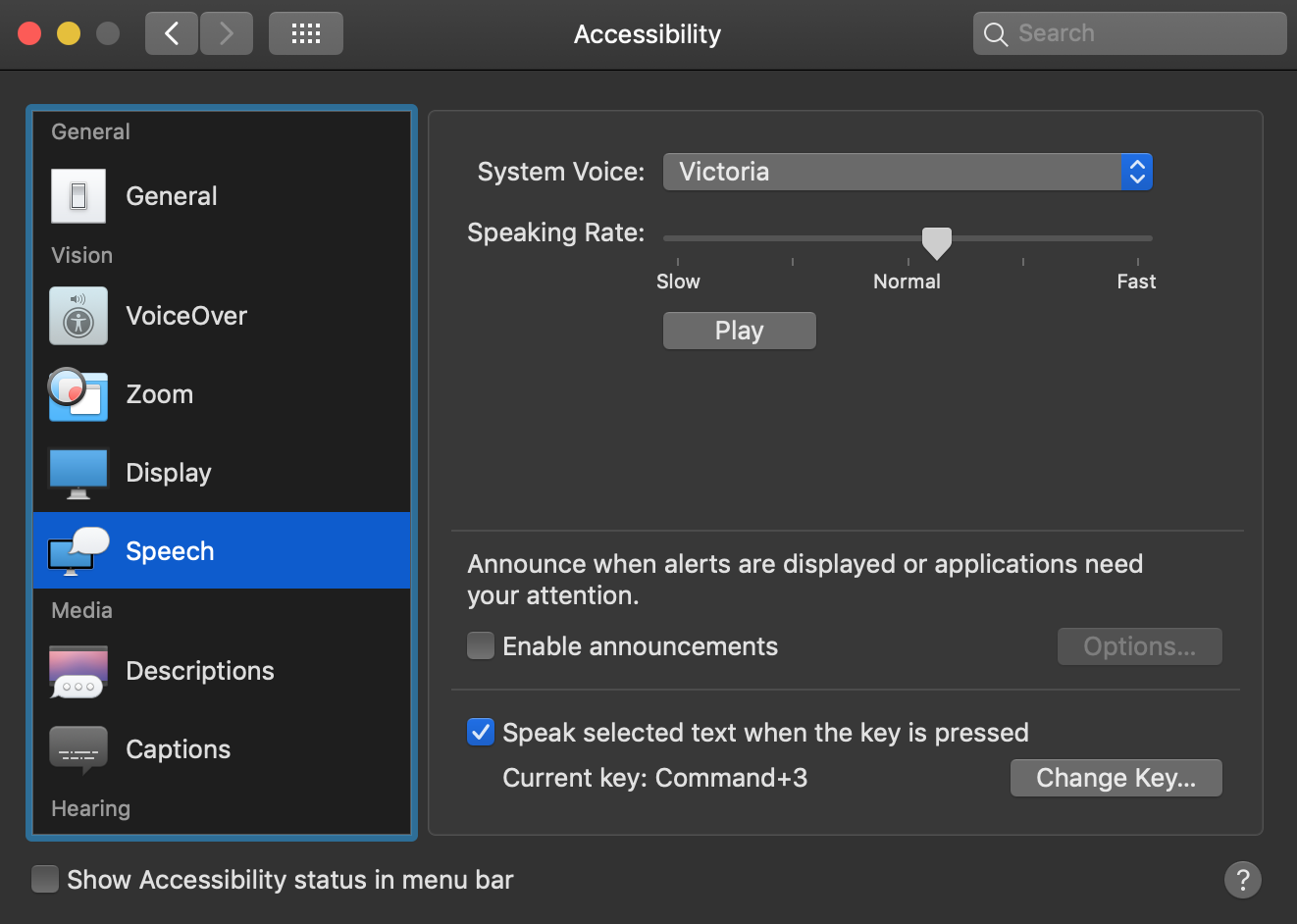
For me to pickup mistakes in my writing, I need the voice to read clearly (not natural sounding) but clear pronunciation and I need to access this voice in any application that uses text across my computer, it needs to also speak quickly and load fast.
In 2013 I tried out some Linux TTS, it only worked in the command line, and I had no idea at the time on how to pipe text from the application I was using to that voice in a usable way. I also found that the voices were slower and the pronunciation was not good enough to pick up mistakes in my writing. Some people suggested using online TTS services and that seams to be the preferred method for TTS now, not just in Linux but all over as you can get a better more natural sounding voice built with machine learning and running on a very powerful system. However this is also not what I want, I want to work off-line sometimes and I don’t like the idea of sending everything I read and write to someone else’s computer (the cloud) for analyses.
In 2019 I started playing around with Arch and Arch distro’s of Linux. I found some software called Light Read that solved the command line to keyboard shortcut integration function and integrated it with Festival TTS. Its a program written in Go that makes Festival read things from anywhere on your system (only for Arch Linux). I to this day have not been able to get Light Read to work. Its old software that has had no updates for years. I also started to learn a little Python coding and have been using Linux for my server for a long time and feeling more confident on trying to get the integration working myself.
Now I’m writing this as much for my self as anyone else as I work towards getting a usable TTS for Linux so I can finally ditch my dependence on OSX and have this document to reference when ever I need to install a new system.
Arch has I think some of the best documentation in the Linux world and their list of TTS software for Linux is the biggest I have found. Currently I’m using Arch as my preferred distro with the KDE desktop environment. I not only like the documentation that Arch has, I also like that there is no company behind it, its maintained by a community. It’s also super fast even on old hardware.
The current speech engines I’m working with to see if I can get a working solution are:
Mimic, Festival, Espeak_ng and swift; there are many others too, have a look at this list to see more TTS systems.
My solutions for this in KDE and Gnome
The below two examples use a TTS engine and xsel which can take any highlighted text on your system and pipe that text into files and applications.
KDE example: Adding a bash command to a custom keyboard shortcut
The first image shows a command that copies highlighted text to a file and then uses festival tts to speak the words from that file. The file is over written every time the command is executed. The second command stops the tts engine (sometimes you start the tts on something and wish to stop it).


Gnome example: Adding a bash command to a custom keyboard shortcut
Open system settings then go to: Keyboard » Customise Shortcuts » Custom Shortcuts » +:
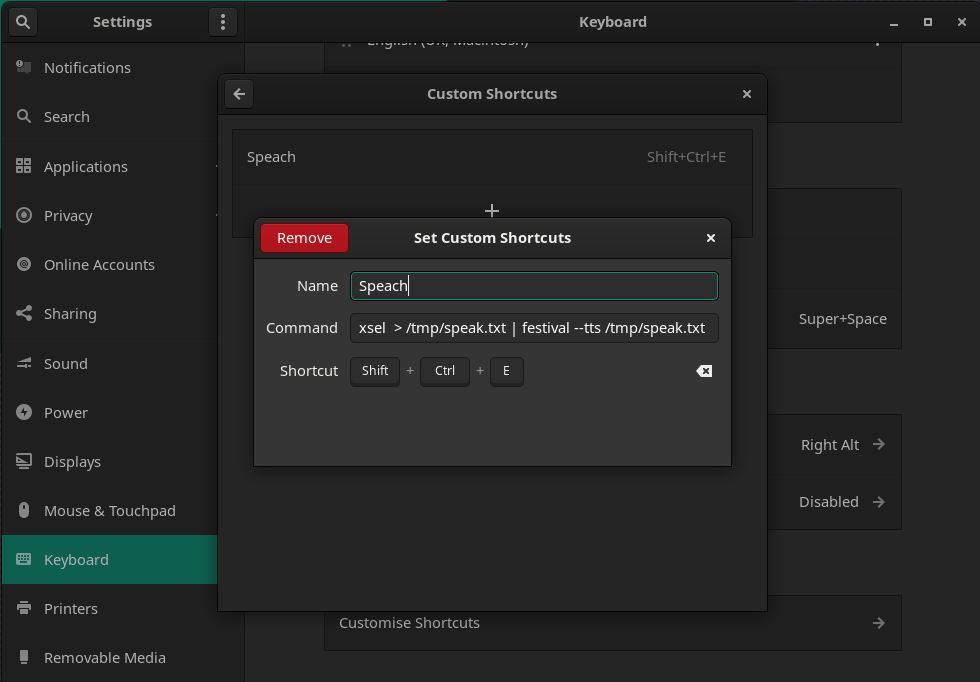
To get your own working tts system with this setup, copy and modify the commands you want to use from the below examples into the custom key shortcuts and make sure you have the software you need for them installed. Then assign a keyboard shortcut to run the script.
Installing software
Most Linux distro’s now have nice gui software centres to install a wide range of software, different distro’s have different package management and syntax for interacting with them.
Debian and Ubuntu install software like this:
sudo apt install espeak-ng
Red Hat, CentOS, rocky Linux, etc install like this:
sudo yum install espeak-ng
Arch based distros install like this:
sudo pacman -S espeak-ng
(where espeak-ng is the name of the package you want to install).
Implementation
The rest of this article will show working examples using Mimic, Festival, Espeak-ng and Cepstral Swift. For my use case I would rank the tts engines I tried like this:
-
Mimic (with the slt voice)
-
Festival (with the default voice)
-
Cepstral (with the Millie voice)
-
Espeak-ng (all voices sound bad)
Updates to this article based on my real world use of this system will be added below
I’m not experienced at writing bash scripts! I now know an easier way to do some of the below examples. We need to use the full path for every program we want to call in the scrip instead of the terminal shorthand:
/usr/bin/xsel | /usr/bin/festival -tts | /usr/bin/pkill xsel
This means we can pipe text strait into festival without first copying it to a text file.
To find out the full path to any program you want to call, use the which command.
which festival
Printes: /usr/bin/festival
Depending on the speed of your system you may need to add a delay between copying the text to the file and starting speaking. We can do this by using the ‘sleep’ command, for my system a delay of 0.3 seconds worked fine:
xsel > /tmp/speak.txt | sleep 0.3 | mimic -f /tmp/speak.txt | pkill xsel
If you often read long texts or if your running this on a low power computer like a rasbary pi then you may need a longer delay.
Mimic
The setup that worked and lets me use TTS in KDE like I do in OSX by adding this line to a custom keyboard shortcut in KDE or Gnome.
xsel > /tmp/speak.txt | sleep 0.3 | mimic -f /tmp/speak.txt | pkill xsel
I further optimised this by adding some configuration options that change the pitch and speed of the voice:
xsel > /tmp/speak.txt | mimic -voice slt --setf duration_stretch=0.85 --setf int_f0_target_mean=165 -f /tmp/speak.txt | pkill xsel
Stop mimic with:
pkill mimic
What do these commands and switch’s do:
xsel > my_file_name.txt (over rights the text in the file with highlighted text)
mimic (calls the mimic tts engine to start speaking)
-voice slt (sets the voice to the slt voice)--setf duration_stretch=0.75 (makes it speak 25% faster (1 = normal speed and 1.5 in slower 50%)).
--setf int_f0_target_mean=200 (makes the pitch higher and =1 would make the pitch very low).
-f (means read text from file)
pkill xsel (stops the computer starting a new process for xsel every time this command is run).
There are quite a few voices installed with Mimic, the voice slt was my favourite. Type: mimic -lv in terminal to see a list of installed voices. Type: man mimic to see all the options and switches.
Mimic is built on flite tts and the commands are the same as far as I can see.
Festival
Similar to Mimic, use this line to make Festival speak text from a custom command by using the following line to use festival in the default configuration. Bind a keyboard command to this command in KDE or Gnome to start Festival TTS.
xsel > /tmp/speak.txt | festival --tts /tmp/speak.txt | pkill xsel
Bind a second keyboard command to stop Festival. (Needed for when you want to stop reading something!)
pkill audsp
Dependencies:
alsa-utils
Pulse Audio
festival
xsel
git (if on Arch)
Configuration
To see what festival voices you have installed, open a terminal and type: festival
then in the festival prompt, type (voice.list) to see the list of voices you have installed.
festival > (voice.list)
You can test out the voices by selecting it in the festival prompt, copy the voice you want to try from the above command and add ‘voice_’ to the front of it like this:
festival> (voice_us2_mbrola)
Now use the ‘SayText’ command to try out the voice you selected above:
festival> (SayText "Hello from Arch Linux")
Once you have found a voice you like, you can set it as the default festival voice like this:
(set! voice_default 'voice_nitech_us_rms_arctic_hts')
Changing the speaking speed:
edit the file of the voice you want to change the speech speed, on my system this is the file for the Kal voice:
/usr/share/festival/voices/english/kal_diphone/festvox/kal_diphone.scm
sudo nano /usr/share/festival/voices/english/kal_diphone/festvox/kal_diphone.scm
Then look for the section ‘Duration prediction’. On my system for the kal voice this is on line: 216. Then change the number 1.1 to a higher or lower number:
(Parameter.set 'Duration_Stretch 1.1)
Change it to a hire or lower number and save the file (Control+E » y » Enter). Restart festival and repeat until you have the speed you like. In the Omilo GUI (below) its also possible to change the reading speed.
Festival can be configured by creating a $HOME/.festivalrc configuration file.
Festival will create an incriminating text file called $HOME/.festival_history with every command sent to it.
Other voices
Here is an old blog post about compiling and installing festival voices on Debian. I was not able to get any of these to work on my system and HTS voices from the AUR would also not compile on my system either. I was able to install two ‘us_en CMU’ voices from the AUR which worked and had really good sound (best sounding TTS I tried on my system). However they used about 800mb of RAM and took about two minutes to load 100 words and start speaking on my old Intel i3 computer. I might come back to this at some point but for now I was not able to get other voices to work (running festival version 2.5.0-4).
Trouble shooting
audio_open_alsa: failed to set hw parameters. Invalid argument.If
If festival gives you this error you need to install the ‘alsa’ package.
Omilo, a GUI for Festival
https://sourceforge.net/projects/o-milo/
(I want TTS from a keyboard command but if you want it from a GUI then this one seams ok in KDE.) This also has one click festival voice installation! I tried to get Omilo to work, without success. I think the reason it might not be working on my system is that it’s new and uses Wayland instead of Xorg. But I have not tried an Xorg system to see if that fixes the problem! I used it a few years ago and it worked on Elementary OS.
Espeak-ng
Similar to Mimic, use this line to make Espeak-ng speak text from a custom keyboard command by using the following line in KDE or Gnome:
xsel > /tmp/speak.txt | espeak-ng -f "/tmp/speak.txt" | pkill xsel
Type man espeak-ng in your terminal to see a list of options for this speech engine.
To stop espeak-ng we can use the following command:
pkill espeak-ng
Cepstral Swift
A closed source voice that works on Linux systems. Personally I don’t find their voices to be better than you can get out of Festival and Mimic.
Cepstral uses the swift command to read text. So to use the work flow for swift we can do it like this:
xsel > /tmp/speak.txt | padsp swift -f /tmp/speak.txt | pkill xsel
To stop the swift engine use this command.
pkill swift.bin
Configuration
This uses the -p switch:
- speech/rate
Integer
Speaking rate (average WPM).
Assume default to be 170WPM.
- speech/pitch/shift
Floating point
Frequency multiplier to use for adjusting pitch. Default is 1.0.
Something like:
padsp swift -p -speech/rate 180 -f /tmp/speak.txt
Trouble shooting
oss_audio: failed to open audio device /dev/dsp
Install oss on your system
Call: padsp swift instead of swift.
Buying the licence code requires contacting the company by phone or email! In the past you could just buy it from the website.
Other software explored during research
Speech-dispatcher
“Speech-dispatcher is a system daemon that allows programs to use one of the installed speech synthesizer programs to produce audio from text input as long as it has a special module or a configuration file for the speech synthesizer programs you want to use. It sits a a layer between programs that would like to turn text into speech and programs who actually do that.” From here
Configuration
Speech-dispatcher can be configured using the configuration file /etc/speech-dispatcher/speechd.conf and "module" specific configuration files in /etc/speech-dispatcher/modules/.
Usage
spd-say “hello from Arch”
Unfortunately the spd-say command dose not seem to be able to read text from a file. I can’t think of a way currently to make Speech Dispatcher work in the same way as I’m doing using Mimic directly above.
To use xsel as we did with Mimic above to speak the text selected using the Speech Dispatcher the command is short and simple.
xsel | spd-say -e | pkill xsel
However this dose not work when placed in a bash scriped (running outside of the terminal) or into the custom command field in KDE/Gnome. I have yet to find a working solution using Speech Dispatcher. Do leave a comment if you know how to make this work.
I also tried this too:
xsel > /tmp/speak.txt && cat /tmp/speak.txt | spd-say -e | pkill xsel
Working in terminal but not when called from KDE.
Trouble shooting
spd-say
Error: setlocale: No such file or directory
Fix: https://github.com/mobile-shell/mosh/issues/144
fix: export LANG='en_US.UTF-8'
In some systems there is a different package called speech-dispatcher-utils that also needs to be installed but in Arch currently speech-dispatcher-utils is part of the speech-dispatcher package.
Testing
sudo systemctl status speech-dispatcherd.service
AT&T TTS
High quality voices that are likely very expensive! You can try a demo on their website, I think these are the best quality client-side voices I have heard.
I expect after looking at their Linux documentation, it would be quite easy to get the same setup for an AT&T voice as I have demonstrated with the above using Mimic, etc and xsel to read text from anywhere on the system.
Links:
Arch - list of TTS software: https://wiki.archlinux.org/title/List_of_applications#Speech_synthesizers
Arch wiki festival: https://wiki.archlinux.org/title/Festival
Festival website with voice demo: https://www.cstr.ed.ac.uk/projects/festival/morevoices.html
Festival code: https://github.com/festvox/festival
Festival Manual (For festival 1.4.0): https://www.cstr.ed.ac.uk/projects/festival/manual/
TTS compare: https://linuxreviews.org/Text_to_Speech_synthesis_software
About festival: https://linuxreviews.org/Festival
Make festival use better voices: https://teknologisuara.blogspot.com/2011/11/howto-make-festival-tts-use-better.html & https://ubuntuforums.org/showthread.php?t=751169&page=12
Festival voice demo: http://festvox.org/voicedemos.html
Festival voice download: http://hts.sp.nitech.ac.jp/?Download#w6dddb75
Mycroft tts engine options: https://mycroft-ai.gitbook.io/docs/using-mycroft-ai/customizations/tts-engine
Flite useful to understand mimic better: https://github.com/festvox/flite
Chang reading speed in festival: https://festival-talk.festvox.narkive.com/RUAJ5rAQ/how-to-make-text2wave-speak-faster
xsel usage: https://www.techrepublic.com/blog/linux-and-open-source/use-xsel-to-copy-text-between-cli-and-gui/
I’m going to end this hear and make updates to this if I find out anything new. I may at any time move this information to another platform. Anyone can use or reuse this information. If you maintain a wiki page or provide documentation for any open-source projects and this was useful, feel free to copy this into your own documentation.
I added a second post about this looking at A.I. voices, you can read it here.